


search製品名・スペックから検索







速報! NVIDIA H100について 特別寄稿 笠原一輝
NVLinkでスケールアウト、浮動小数点演算器の倍増、TensorコアでFP8サポートが特徴のNVIDIA H100
 NVIDIA H100 GPUを8つ搭載しているDGX H100(写真提供:NVIDIA)
NVIDIA H100 GPUを8つ搭載しているDGX H100(写真提供:NVIDIA)
NVIDIAがGTC 2022で、新しいAI/HPC向けのGPUとなるNVIDIA H100 GPU(以下NVIDIA H100)を発表した。COBOLを造ったコンピューター科学者グレース・ホッパー(故人)からとったHopper(ホッパー)の開発コードネームを持つ新しいアーキテクチャを採用したNVIDIA H100は、一昨年の発表以来AI/HPC用の演算用システムとして業界標準だったNVIDIA A100 GPU(以下NVIDIA A100)を置きかえるものとなる。同時にNVIDIA H100を8つ搭載したDGX H100も投入することが発表されている。
このNVIDIA H100でNVIDIAは重要な拡張をいくつか行っている。特にAIの学習やHPC向けのDGXシリーズを導入しているユーザーにとって注目ポイントは3つある。1つ目は、DGXの8GPUのスケールアップに利用されているNVSwitchが、スケールアウトにも利用できるようになり、最大で32台のDGXをInfiniBandよりも高速で広帯域なNVLinkで接続できるようになったこと。2つ目は内蔵されている浮動小数点演算の演算器が倍増され、同じクロック周波数であればA100の2倍のスループットを実現できること、そして最後にNVIDIAのGPUで高速な演算を実現している肝となっているTensorコアがFP8に対応したことだ。
NVLinkが第4世代に、NVSwitchが第3世代になることで、最大32台DGXのスケールアウトをNVLinkで実現可能に
 第3世代のNVSwitch。NVLink Networkなどの新機能に対応しており、最大で256個のGPUを1クラスターとして扱うことができる(写真提供:NVIDIA)
第3世代のNVSwitch。NVLink Networkなどの新機能に対応しており、最大で256個のGPUを1クラスターとして扱うことができる(写真提供:NVIDIA)
AI学習(Training)やHPCにDGXサーバーを利用しているユーザーにとって今回のNVIDIA H100で最も注目なのは、GPUとGPUを接続するインターコネクトのNVLinkと、そのNVLinkをスイッチングする役割を持つ外部チップのNVSwitchだ。
NVLinkは近年のNVIDIAのGPUに実装されているGPUとGPU、およびGPUとCPUなどを接続するインターコネクトとして導入された(ただ、NVLinkはNVIDIAのプロプライエタリなバスで、現状CPUでサポートしているのはIBMのPowerだけなので、実質的にはGPUとGPUを接続するインターコネクトとして利用されている)。一般的なPCI Expressなどに比べて低レイテンシで、広帯域、高い電力効率でやりとりを行うことができるため、複数のGPUを束ねて1つのGPUとして利用する時に、性能低下を防いで高いスループットを実現することを可能にしている。
 第4世代のNVLinkと第3世代のNVSwitchの特徴(出展:Essence of Hopper、NVIDIA)
第4世代のNVLinkと第3世代のNVSwitchの特徴(出展:Essence of Hopper、NVIDIA)
NVLinkは4レーン片方向で25GB/秒、双方向で50GB/秒の通信速度を実現している。従来世代のNVIDIA A100では12個のNVLinkコントローラを内蔵していたためチップ全体で最大600GB/秒の帯域幅を実現していたが、NVIDIA H100では18個に増やされており、そのため帯域幅は最大900GB/秒に拡張されている。
NVIDIA H100に導入されている第4世代のNVLinkではそうした帯域幅の向上と共に、新しい「NVLink Network」と呼ばれる新しいモードが追加されている。これはNVLinkのアドレススペースをネットワークにも拡張したもので、従来よりも多くの数のGPUを1つのアドレススペースでサポートすることが可能になる。具体的には最大で256GPUまでスケールすることが可能になっているのだ。
 左側が従来のNVLink/NVSwitchで256個のGPUを接続する場合(DGX A100を32台接続する場合)でDGX同士はInfiniBandで接続している。右側は第4世代のNVLinkと第3世代のNVSwitchを利用して256個のGPUを接続する場合(DGX H100を32台接続している状態)(出展:Essence of Hopper、NVIDIA)
左側が従来のNVLink/NVSwitchで256個のGPUを接続する場合(DGX A100を32台接続する場合)でDGX同士はInfiniBandで接続している。右側は第4世代のNVLinkと第3世代のNVSwitchを利用して256個のGPUを接続する場合(DGX H100を32台接続している状態)(出展:Essence of Hopper、NVIDIA)
NVIDIA A100時代のNVLinkでは、NVSwitchを6つ利用して8つのGPUを接続することができていた(DGX A100がその端的な例だ)。その先、例えばDGX A100をスケールアウト(サーバーとサーバーを何らかのネットワークなど接続してクラスターとして利用すること)する場合には、InfiniBandなどの別のネットワークを利用して接続する形になっていた。
しかし、今回のNVIDIA H100では第4世代のNVLinkではNVLink Networkを利用して、DGXを最大32台、GPUの数に換算すると256台までスケールアウトして利用することができる。さらにNVSwitchには「Sharp」(シャープ)と呼ばれる、InfiniBandなどで使われてきたアクセラレーション機能を導入しGPUとGPUが通信するときに無駄なやりとりを削減して実効帯域をあげる仕組みが入れられている。これらにより必要な帯域を確保したままGPUを256個までスケールアップ/スケールアウトできるようになっているのだ。
これにより、従来のInfiniBandで32台のDGX A100をスケールアウトしていた場合とNVSwitchによりNVLinkで32台のDGX H100をスケールアウトしている場合を比較すると、後者の場合にはすべてのGPUとGPUがデータをやりとりする場合の帯域幅は57.6TB/秒に達しており、DGX A100が32台の場合の6.4TB/秒と比較して実に9倍になる。これにより、実効レートが向上し、性能の低下が少ない状態で256個のGPUクラスターを利用することが可能になるのだ。
 DGX A100で1024個のGPUをクラスタ-化する場合にはInfiniBandだけを利用するが、DGX H100で1024個のGPUをクラスター化する場合にはNVLinkとInfiniBandを組み合わせる(出展:Essence of Hopper、NVIDIA)
DGX A100で1024個のGPUをクラスタ-化する場合にはInfiniBandだけを利用するが、DGX H100で1024個のGPUをクラスター化する場合にはNVLinkとInfiniBandを組み合わせる(出展:Essence of Hopper、NVIDIA)
こうした32台のDGX H100から構成されているクラスターをさらにスケールアウトしたい場合には、InfiniBandなどを利用することになる。NVIDIAは今回次世代のInfiniBandのNICとしてConnectX7 NDR NIC、さらにはQuantum 2 NDR Switchなどを導入しており、それらを利用することで、32台のDGX H100を1つのサブクラスターとして、128台のDGX H100を1つのクラスターとしてスケールアウトできるようにする。この場合の性能は2EFLOPSに達し、ついに性能の単位がエクサに達することになる。
このように、今回のNVIDIA H100では、NVLinkが第4世代になり、NVSwitchも第3世代になったことで、DGXの内部でスケールアップする場合にも、DGXを複数つないでスケールアウトする場合にもNVLinkを利用することが可能になり、実効性能が大幅に上がった、それこそがNVIDIA H100最大の強化点と言っても過言ではない。
SMに内蔵されている演算器が倍になりFP演算性能は倍に、TensorコアはFP8に対応
 NVIDIA H100のハイレベルのブロック図(出展:Essence of Hopper、NVIDIA)
NVIDIA H100のハイレベルのブロック図(出展:Essence of Hopper、NVIDIA)
NVIDIA H100は、GH100という開発コードネームがつけられたダイがベースになり製品として展開される。NVIDIA A100もGA100という開発コードネームがベースになっていたので、数字の前にアーキテクチャの頭文字のアルファベット+100という数字のコードネームになっているという点では全く同様になっている。
そのGH100と、前世代となるGA100の、ダイレベルでのスペックを見ると以下の表のようになっている。
表1 GA100とGH100の仕様(NVIDIAの資料などより筆者作成)
| GA100 | GH100 | |
| SM | 128 | 144 |
| GPC | 8 | 8 |
| GPC辺りのSM数 | 16 | 18 |
| SMあたりのCUDAコア(FP32) | 64 | 128 |
| GPU全体のCUDAコア | 8192 | 18432 |
| Tensorコア | 第3世代 | 第4世代 |
| Tensorコア数(GPU全体) | 512 | 576 |
| L1データキャッシュ(SMあたり) | 192KB | 256KB |
| L2キャッシュ | 非公開(A100は40MB) | 60MB(H100は50MB) |
| メモリコントローラ | 12xHBM2(512ビット) | 12xHBM3(512ビット) |
| メモリ帯域(最大) | 1555GB/秒(A100-5120ビット) | 3000GB/秒(H100-5120ビット) |
| NVLink | 第3世代/12コントローラ | 第4世代/18コントローラ |
| NVLink帯域 | 600GB/秒 | 900GB/秒 |
| トランジスター数 | 542億 | 800億 |
| GPUダイサイズ | 826平方mm | 814平方mm |
| 製造プロセスノード(TSMC) | 7 nm N7 | 4N(NVIDIAカスタム) |
なお、これらのダイのスペックは仕様上の最大スペックであり、実際には歩留まり(製品を生産した後の良品率)をあげるため、発売される製品ではそれらのフルスペックよりもややスペックが低くなっている。例えばGH100の仕様上のSM数は144基だが、製品となるNVIDIA H100のSM数は132基(SXM5版)となっている。計算上12個のSMが無効にされていることになるが、そうすると歩留まりが向上するため、そうしたことになっていると考えることができる。
 GH100を搭載したSXM5のモジュール(写真提供:NVIDIA)
GH100を搭載したSXM5のモジュール(写真提供:NVIDIA)
GA100からGH100のハードウエアの強化で大きな点はSMが増えていることだ。NVIDIAのGPUではGPC>SM>内部演算器とブロックが細分化されているが、GA100もGH100もGPCが8つという基本構造は変わっていない。しかし、GPC1つあたりでみるとGA100ではSM16基という構成になっていたが、GH100ではSM18基になっている。このため、GH100ではSMが最大144基という構造になっている。
 NVIDIA H100のSMの構造をみると、FP32の演算器(CUDAコア)は128個になっている。NVIDIA A100のSMではFP32の演算器は64個になっており、NVIDIA H100では1クロックあたりの処理能力が倍になっていることがわかる(出展:Essence of Hopper、NVIDIA)
NVIDIA H100のSMの構造をみると、FP32の演算器(CUDAコア)は128個になっている。NVIDIA A100のSMではFP32の演算器は64個になっており、NVIDIA H100では1クロックあたりの処理能力が倍になっていることがわかる(出展:Essence of Hopper、NVIDIA)
そしてSMあたりのCUDAコア(FP32)が倍になっていることも見逃せない。これにより、同じクロック周波数で処理できるデータ量は倍になる計算になる。実際、FP16、FP32、FP64などの演算性能はいずれもNVIDIA A100に比べて倍になっており、その最大の由来はこの演算器が倍になっていることだ。
また、キャッシュ階層も強化されており、SM1つ1つに内蔵されているL1データキャッシュは256KBに増やされ、GPU全体でシェアされるL2キャッシュは40MBから50MB(ダイの仕様上は60MB)に増やされている。また、メモリコントローラはHBM3/HBM2e対応になり、HBM3に対応した場合には3000GB/秒と、A100世代の1555GB/秒と比較して2倍の帯域幅が実現されている。
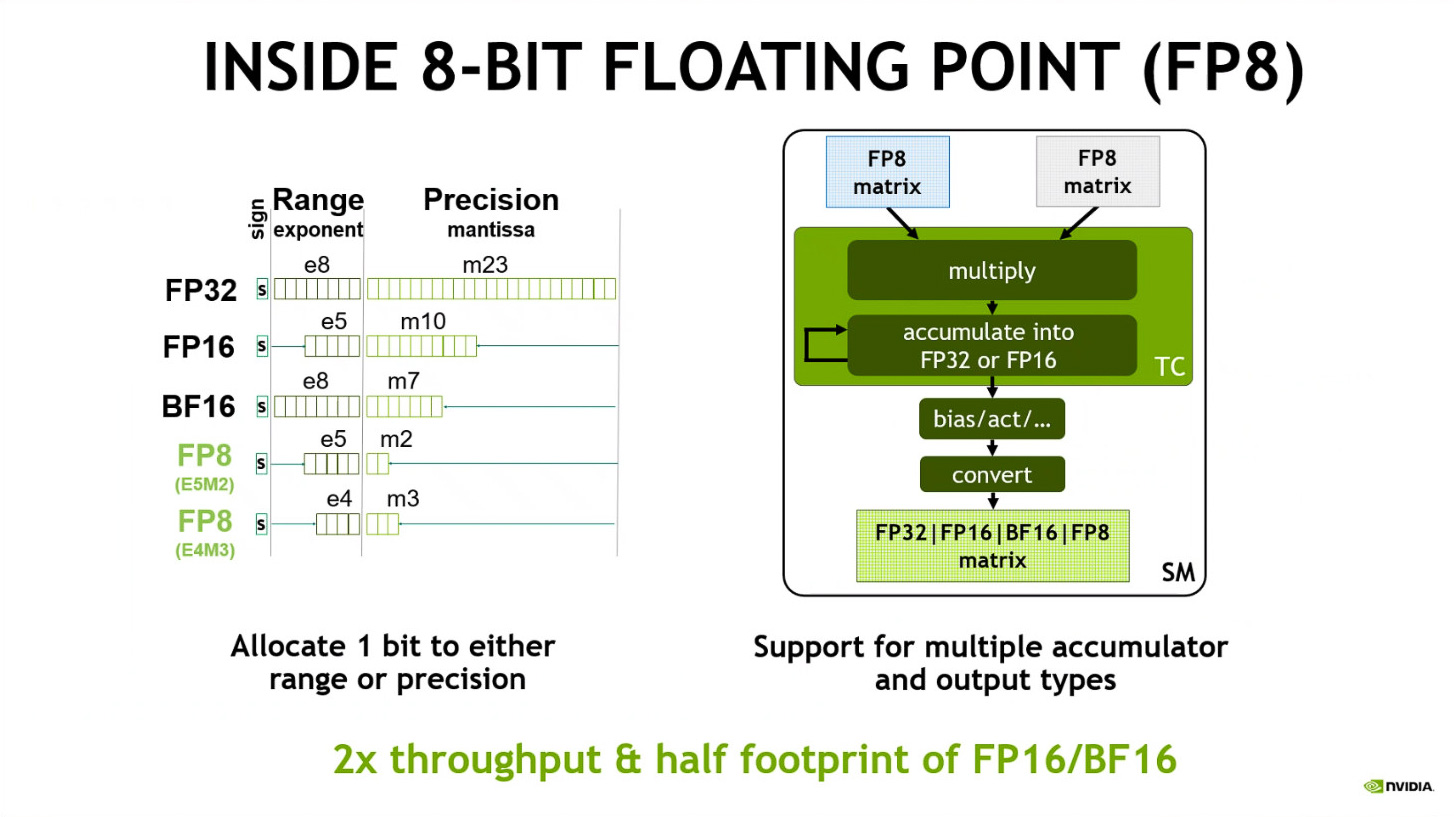 Tensorコアでは新しくFP8をサポート(出展:Essence of Hopper、NVIDIA)
Tensorコアでは新しくFP8をサポート(出展:Essence of Hopper、NVIDIA)
そしてGH100の中で大きな進化を遂げているのが、1つのSMに4つ搭載されているTensorコアだ。Tensorコアは、行列積和 (MMA) 演算を可能にする演算ユニットで、混合精度で行列演算を高速に行うことが可能になっている。従来のA100に搭載されていた第3世代のTensorユニットでは、FP64、TF32、FP32、FP16、INT8の演算を行うことが可能になっていたが、今回のH100ではFP8が利用可能になっている。
FP8は最近INT8と並びAIの演算で活用されるようになってきているフォーマットで、精度を落とすことになるが、AIの学習や推論などでは正確性は落ちないことがわかっているので、FP16などをFP8に置きかえて演算する手法がよく使われている。今回発表されたH100でサポートされているFP8は、E5M2と呼ばれる指数が5ビットで仮数が2ビットというフォーマットと、E4M3という指数が4ビットで仮数が3ビットという2つのフォーマットになる。
表2 NVIDIA A100とNVIDIA H100の演算性能(NVIDIAの資料などより筆者作成)
| 製品 | NVIDIA A100 | NVIDIA H100 SXM5 |
| 最大FP8 Tensor TFLOPS FP16 Accumulate有効時*1 | N/A | 2000/4000*2 |
| 最大FP8 Tensor TFLOPS FP32 Accumulate有効時*1 | N/A | 2000/4000*2 |
| 最大FP16 Tensor TFLOPS FP16 Accumulate有効時*1 | 312/624*2 | 1000/2000*2 |
| 最大FP16 Tensor TFLOPS FP32 Accumulate有効時*1 | 312/624*2 | 1000/2000*2 |
| 最大BF16 Tensor TFLOPS FP32 Accumulate有効時*1 | 312/624*2 | 1000/2000*2 |
| 最大TF32 Tensor TFLOPS*1 | 156/312*2 | 500/1000*2 |
| 最大FP64 Tensor TFLOPS*1 | 19.5 | 60 |
| 最大INT8 Tensor TOPS*1 | 624/1248*2 | 2000/4000*2 |
| 最大FP16 TFLOPS (Tensor未使用時)*1 | 78 | 120 |
| 最大BF16 TFLOPS (Tensor未使用時)*1 | 39 | 120 |
| 最大FP32 TFLOPS (Tensor未使用時)*1 | 19.5 | 60 |
| 最大FP64 TFLOPS (Tensor未使用時)*1 | 9.7 | 30 |
| 最大INT32 TOPS*1 | 19.5 | 30 |
※1 NVIDIA H100のスペックは変更される可能性がある
※2 スパース性を利用した場合
そうしたFP8を利用して演算すると、4096FLOPS、スパース性を利用すると8192FLOPSというペタを超える性能で演算することが可能になるとNVIDIAは説明している。
コンフィデンシャルコンピューティングがMIGでも利用可能に、秘匿性の高いアプリケーションもGPUで処理可能に

Thread Block Cluster(出展:Essence of Hopper、NVIDIA)
今回のNVIDIA H100ではソフトウエア面での拡張もいくつも入っている。例えば、CUDAの拡張により、GPCをクラスターとして定義し、同じスレッド処理はできるだけ同じGPC内のSMで済ませるようにすることでデータロカリティの問題を解決する「Thread Block Cluster」という機能が追加されている。また、SMがメモリやキャッシュにデータ転送を行う際GPU側のリソースを使わずに、DMAのような処理を行うTMA(Tensor Memory Accelerator)というハードウエアが実装され、それが利用可能になることでCUDA実行時の効率が高められている。
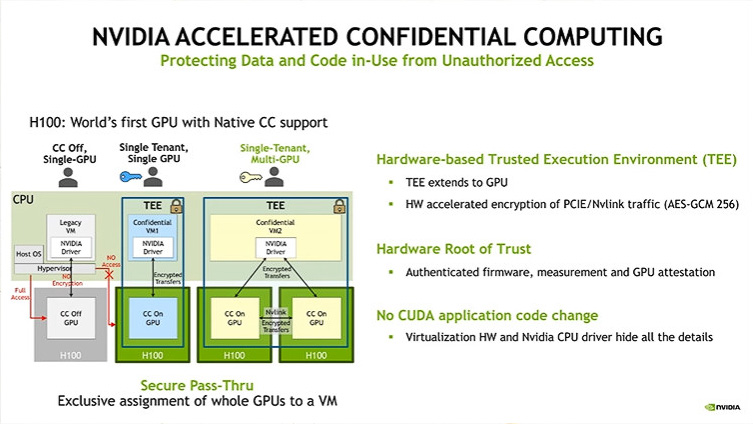 コンフィデンシャルコンピューティング(出展:NVIDIA Hopper Architecture、NVIDIA)
コンフィデンシャルコンピューティング(出展:NVIDIA Hopper Architecture、NVIDIA)
また、データセンターにDGXなどを格納してNVIDIA H100を利用するユーザーにとって注目したのは、コンフィデンシャルコンピューティングへの対応とMIG(Multi-Instance GPU)機能の強化だろう。
コンフィデンシャルコンピューティングとは、CPUやGPUの中にデータが保護されているメモリ領域(TEE:Trusted Execution Environment)を作り出し、そこに対して他のアプリケーションなどからのアクセスを拒否する仕組みを用意することで、最近のデータセンター向けCPUなどでは標準的な機能として搭載されている。NVIDIA H100ではGPUとして初めてコンフィデンシャルコンピューティングに対応し、例えば医療データなどのプライバシーへの最大の配慮が必要なデータなどを保護しながら、AIの学習に利用することなどが可能になる。
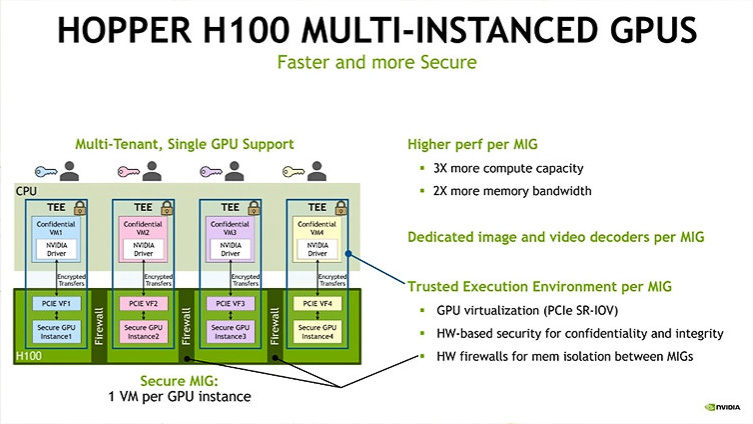 MIGで分割されたテナントにもそれぞれTEEを作成することができる(出展:NVIDIA Hopper Architecture、NVIDIA)
MIGで分割されたテナントにもそれぞれTEEを作成することができる(出展:NVIDIA Hopper Architecture、NVIDIA)
NVIDIA H100では、前世代で導入されたMIG(Multi-Instance GPU)でもコンフィデンシャルコンピューティングの機能を利用することができるようになっている。MIGではGPUを最大7つの部分に分割し、それぞれをテナント(クラウドサービスプロバイダーが顧客に提供するサービス単位)に割り当てて利用することが可能になっている。この時、それぞれのテナント、自分に割り当てられたMIGによるGPUそれぞれにTEEを作成することができるため、テナントはより高い秘匿性でクラウドGPUを利用することが可能になる。
DGX H100はFP8に対応することでDGX A100の6倍以上の性能を発揮、出荷は第3四半期から順次行われる
 DGX H100の内部構造(写真提供:NVIDIA)
DGX H100の内部構造(写真提供:NVIDIA)
こうした強化により、NVIDIA H100を8つ搭載したDGX H100単体の性能も大きく引き上げられている。従来のDGX A100が5PFLOPS(AI演算時)だったのが、DGX H100では32PFLOPS(AI演算時/FP8)と6倍以上になっている。
表3 DGX A100とDGX H100のスペック(NVIDIAの資料などより筆者作成)
| DGX A100 | DGX H100 | |
| GPU | 8xNVIDIA A100 | 8xNVIDIA H100 |
| NVSwitch | 6 | 4 |
| 演算性能 | 5PFLOPS(AI/FP16) | 32PFLOPS(AI/FP8) |
| GPUメモリ(システム全体) | 640GB | 640GB |
| CPU | 第3世代EPYC 7742×2 | 未公表のx86 CPU×2 |
| システムメモリ | 1TB(2TBはオプション) | 2TB |
| ストレージ | 15TB(30TBオプション、NVMe) | 30TB(NVMe) |
| InfiniBandアダプタ | NVIDIA ConnectX-6(最大200Gb/秒) | NVIDIA ConnectX-7(最大400Gb/秒) |
| イーサネット | NVIDIA ConnectX-6(最大200Gb/秒) | NVIDIA BlueField-3 DPU(最大400Gb/秒×1、200Gb秒×1、いずれもIBとして利用可能) |
| 最大システム消費電力 | 6.5kW | 10.2kW |
なお、今回NVIDIAはDGX H100のCPUをスペック上は公表しておらず「Dual x86」とだけ述べていて、デュアルソケットのx86プロセッサーであることしかわからない。AMDのEPYCであれば、既に新製品となる「3D V-キャッシュ搭載第3世代EPYC」を発表したばかりで、CPU名を公表するのに差し支えは無いはずだが、今回公表されていないということは3月中にIntelが出荷すると既にアナウンスしているが正式発表はされていない次世代Xeon Scalable Processorsとなる「Sapphire Rapids」なのかもしれない。この点は今後のNVIDIAの公表を待ちたいところだ。
また、システムメモリー(CPU側のメモリ)は、DGX A100では1TBが標準仕様で、BTOで2TBにすることができるようになっていたが、DGX H100では最初から2TBが標準だ。ストレージも同様で、DGX A100では15TBが標準仕様で、BTOで30TBにすることができていたが、DGX H100では30TBが標準となっている。
またネットワーク周りの強化もポイントでInfiniBandのアダプターはConnectX-7にアップグレードされ、400Gb/秒のInfiniBandを利用することが可能になっている。また、イーサネットはデュアルポートのBlueField-3 DPUにアップグレードされており、400Gb/秒のInfiniBand/イーサネットと200Gb/秒InfiniBand/イーサネットとして利用することができる。
NVIDIAによれば、NVIDIA H100やそれを搭載したNVIDIA DGX H100は、今年の第3四半期から順次出荷が開始されるという。今でもAIの学習やHPCの演算リソースは限られているという声はよく聞くが、そうした組織や企業であれば、置きかえるだけで性能が6倍になるDGX H100は再び奪い合いになると考えられる。DGX H100のオーダーを考えているなら、早めに検討しておいた方がよいかもしれない。
笠原 一輝
NVIDIA GTC Spring 2022 (Omniverse / AI) ダイジェストレビューのご案内
株式会社ジーデップ・アドバンスは来る4月5日(火)に、NVIDIA社と共催で「NVIDIA GTC Spring 2022 (Omniverse / AI) ダイジェストレビューセミナー」と題し、NVIDIA GTC22 Springを振り返り 特にAIとOmniverseをフィーチャーした日本語解説のWebinarを開催致します。
GTCはエヌビディアが毎年最も力を入れる技術イベントで、グラフィックス・ハイパフォーマンスコンピューティング(HPC)・AI・ネットワークといった幅広い分野にわたって、最新の研究成果やユーザー事例が全世界同時開催のグローバルイベントで発表され、研究やテクノロジーへ関心を持つ多くの方々に注目されております。
本セミナーでは「GTC22 Spring」で発表のあった内容について、CEOジェンスン フアンによる基調講演の内容も織り交ぜながら、「AI」と「Omniverse」それぞれの分野に分け、専任のご担当者を迎えて日本語で詳しく解説を行います。NVIDIA社の最新のAI関連ハードウェアアーキテクチャやソフトウェアスタック、サービス動向など、Omniverseについては今回、ISSAC SIMに関するセッションも追加致しました。いずれも日本語での解説となりますので、皆様のGTCの情報整理も踏まえ今後の研究やビジネスのお役に立てれば幸いです。


