NVIDIA H200 Tensor core GPU NVIDIA H200 NVL 141GB PCIe

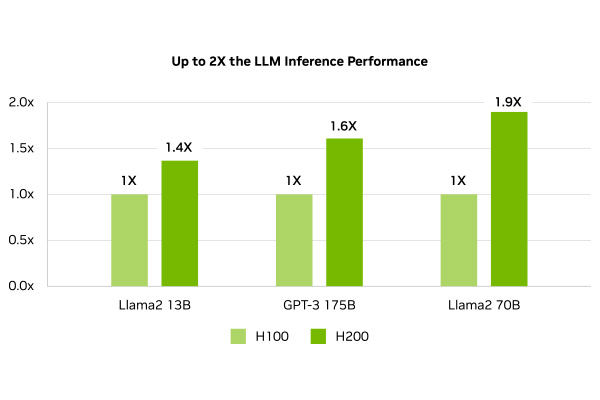
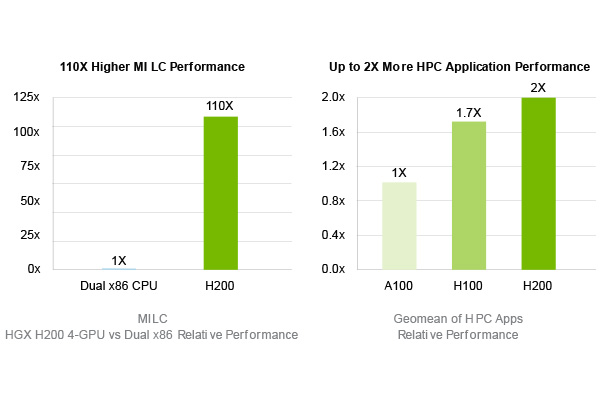
NVIDIA® H200 NVL は、最新のGPUアーキテクチャ「Hopper」を採用し、大容量141GBのHBM3eメモリと4.8TB/sの帯域幅を実現し生成AIに最適化されたGPUです。700億パラメータの大規模言語モデル 「Llama2 70B」の推論を前モデルである、NVIDIA H100と比較して1.9倍、1750億パラメータの大規模言語モデル「GPT3-175B」の推論で1.6倍高速化し、HPCアプリケーションにおいてはCPU (Xeon® Platinum 8480+ 2CPU) に比べて110倍の高速化を実現します。
これにより、大規模言語モデルの開発や、複雑なシミュレーションなどの高度な計算処理を短時間で実行可能になりました。また、NVIDIA AI Enterpriseの5年サブスクリプションを付属することで、より円滑なAI開発環境を提供します。
これにより、大規模言語モデルの開発や、複雑なシミュレーションなどの高度な計算処理を短時間で実行可能になりました。また、NVIDIA AI Enterpriseの5年サブスクリプションを付属することで、より円滑なAI開発環境を提供します。
NVIDIA® H200は、大規模言語モデル研究の新たな可能性を広げる強力なツールとして、従来のGPUでは困難だった大規模なモデルのトレーニングと推論を短時間で高精度に行うことができます。HBM3eメモリの大幅な容量増加により、より複雑なモデルを扱えるようになり、研究の幅が広がります。
さらに、2枚の「H200 NVL」をNVLink™で接続することにより282GBの広大なメモリ空間を実現。各GPU間は900GB/sの広帯域で疎通可能となり、生成AIのような大規模AIモデルの学習に最適です。
※本製品は消費電力が非常に高くNVIDIAが認定したシステムにのみ搭載可能です。動作認証済のシステムや搭載方法については弊社にご相談下さい。 ※NVLinkでのGPU接続は、NVIDIA H100 NVL を2枚接続する際に有効です。異なるGPUカードとの接続は動作保障外となりますのでご注意下さい。
【レンタルでの導入も可能】 GPUレンタルのメリットとして初期投資の削減が可能になります。 高性能なGPUを購入する必要がなく、必要なときだけレンタルできるため、コスト効率をご検討される方にお勧めです。 ご希望の場合、見積もり画面から選択できます。
※本製品は消費電力が非常に高くNVIDIAが認定したシステムにのみ搭載可能です。動作認証済のシステムや搭載方法については弊社にご相談下さい。 ※NVLinkでのGPU接続は、NVIDIA H100 NVL を2枚接続する際に有効です。異なるGPUカードとの接続は動作保障外となりますのでご注意下さい。
| NVIDIA H100 for PCIe | NVIDIA H100 NVL for PCIe | NVIDIA H200 NVL for PCIe | |
| アーキテクチャ | Hopper | Hopper | Hopper |
| FP64 | 24 TFLOPS | 30TFLOPS | 30 TFLOPS |
| FP64 Tensor コア | 30 TFLOPS | 60TFLOPS | 60 TFLOPS |
| FP32 | 30 TFLOPS | 60TFLOPS | 60 TFLOPS |
| TF32 Tensor コア* | 395 TFLOPS | 835TFLOPS | 835 TFLOPS |
| BFLOAT16 Tensor コア* | 395 TFLOPS | 1,671TFLOPS | 1,671 TFLOPS |
| FP16 Tensor コア* | 1,513 TFLOPS | 1,671TFLOPS | 1,671 TFLOPS |
| FP8 Tensor コア* | 3,026 TFLOPS | 3,341TFLOPS | 3,341 TFLOPS |
| INT8 Tensor コア* | 3,026 TOPS | 3,341 TOPS | 3,341 TFLOPS |
| GPU メモリ | 80 GB HBM2e | 94GB HBM3 | 141GB HBM3e |
| GPU メモリ帯域幅 | 2TB/秒 | 3.9TB/秒 | 4.8TB/秒 |
| デコーダー | 7 NVDEC | 7 NVDEC | 7 NVDEC |
| TDP | 約350W | 350-400W (構成可能) | 最大600W(設定可能) |
| マルチインスタンス GPU | 最大 7 個の MIG(第3世代) | 各 12GB の最大 14 個の MIG | 最大7パーティション(各16.5GB) |
| フォーム ファクター | PCIe Dual Slot | PCIe Dual Slot | PCIe Dual Slot |
| 冷却方法 | Passive | Passive | Passive |
| NVIDIA AI Enterprise | 含む(5年間) | 含む(5年間) | 含む(5年間) |
| 保証 | 3年 | 3年 | 3年 |
- Hopper
- PCIe 5.0
- HBM3e
- 141GB
- [FP64]30 TFLOPS
- [FP32]60 TFLOPS
- FP16/ FP8演算性能
- 3年保証